
Generally, you don't think about how much your instance is using the IAM profile attached to it. You probably care what it can do, and you've spent some time ensuring it's privileged appropriately. This raises the question of whether you should care how often the server invokes the Instance Metadata Service (IMDS).
Most of the time, the answer is probably not. However, I recently ran into a scenario where it did matter. Consider the sequence diagram below:
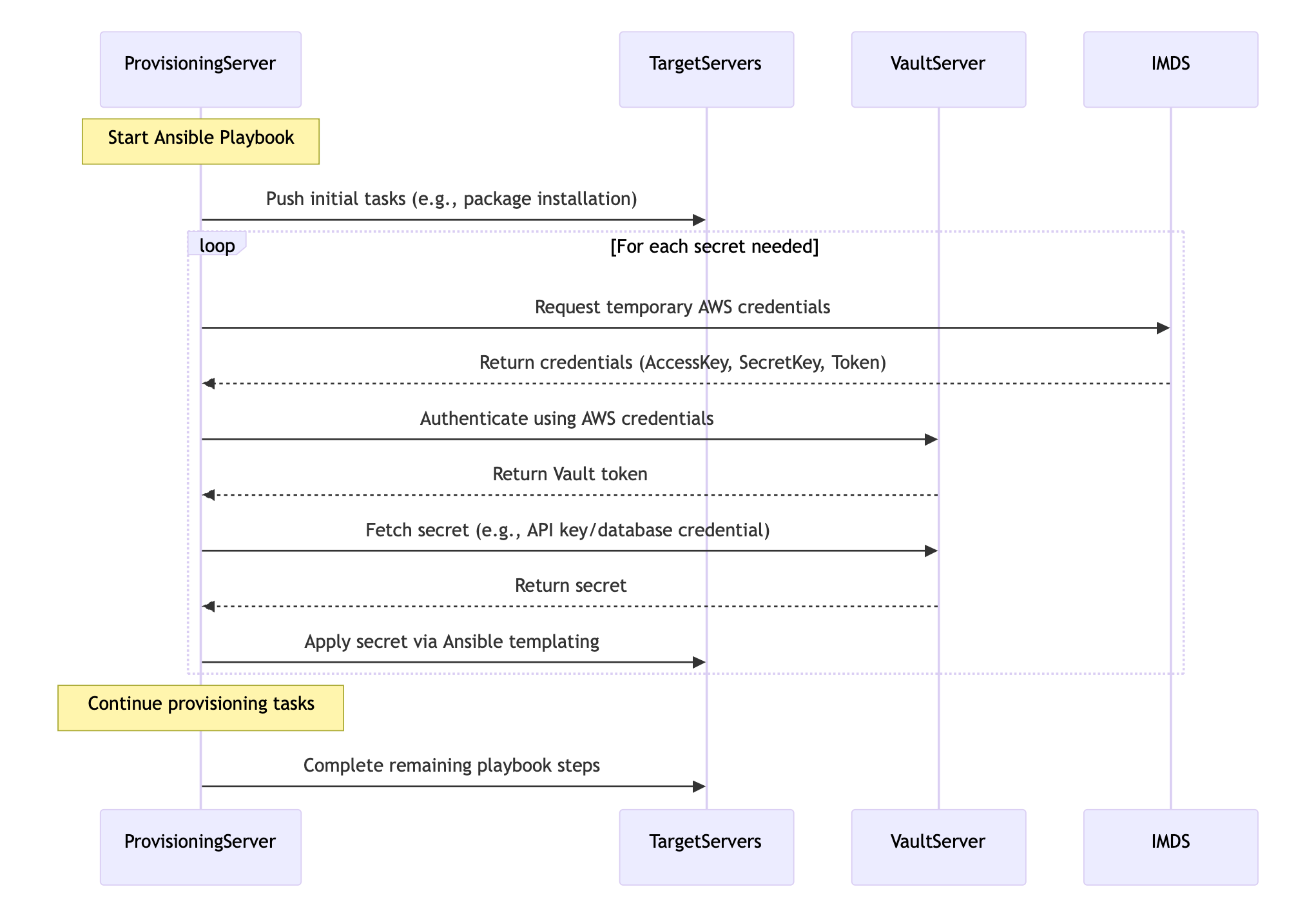
Let's break down the background of that sequence diagram.
We have a ProvisioningServer that can be used programmatically to run Ansible in a push configuration. It might target one server or fifty, depending on the playbook and inventory used.
Some of the tasks in some playbooks template configuration files with sensitive credentials. Now, like any sane person, they aren't stored in Git but a secrets engine. In this case, Hashicorp Vault.
The authentication method for this provisioning server to Vault is using IAM instance profiles. To do this, the server will make a call to IMDS, get credentials, and then auth to Vault.
After fetching the secret, Ansible continues on, repeating any authentication and credential fetches.
The Problem
Now, as mentioned, Ansible sometimes pushes to dozens of servers at once, leveraging the magic of the multiplexing setting. Over time, we'd notice that Ansible would occasionally fail when fetching the secret. We'd attribute this to various causes, such as network instability or swapping from HashiVault lookup to the KV Get module in our configuration.
The errors in the log were vague: "An exception occurred during task execution." Ansible suggested using -vvv for the whole trace, but that didn't reveal any more details.
We tried a lot of fixes:
- Refactoring the HashiVault lookups to be more dry
- Toying with Multiplexing and timeout settings in Ansible and the HashiVault module
- Reducing the number of nodes that are pushed to
None of the above worked. Sometimes, there were improvements; 3 out of 5 jobs failed instead of 5 out of 5, but overall, it was still an issue and prevented reliable configuration management.
On a whim, I enabled all the debug logging I could for Ansible, the servers being targeted, and HashiCorp Vault. I even made sure to capture network traffic. What I found surprised me.
What the Debug Logs Revealed
Upon investigating the millions of log lines generated by enabling debug logging on everything, I discovered an interesting trend. I always assumed that the HashiVault module cached the authentication tokens. It implies that, depending on how you retrieve the secrets from Vault, you may or may not need to re-authenticate each time. However, both network traffic and Vault logs showed a significant amount of traffic going to Vault—more than just fetching secrets.
As a test, I tried to get rate-limited by Vault. I would fetch a token and fetch as many secrets as I could, as fast as I could. I eventually hit an issue, but it wasn't materializing the same error as Ansible. I stepped a little closer to the same layout as production. I would use IAM auth for Vault. That returned the same error with the same profile of logs and traffic.
Seeking A Second Opinion
I'm fortunate enough to have premium support with AWS, so I reached out to them asking about rate limiting with IMDS. Their response wasn't great, but it was enough to get me where I needed to be.
First they talked about the MetadataNoToken metric in CloudWatch. I was already using IMDSv2, so that really didn't help. But an offhand comment by the support agent about checking for packet loss on the network interface. That led me to the linklocal_allowance_exceeded metric in ethtool
About Link-Local Addresses and Their Limits
Amazon uses link-local addresses for various services. This is your 169.254.0.0/16 range. IMDS is probably the most well known one. It uses 169.254.169.254 but there are others such as Route53 resolver queries and queries for the Amazon Time service.
Buried on a page about accessing the instance metadata is a small section on a packet-per-second (PPS) limit.
There is a 1024 packet per second (PPS) limit to services that use link-local addresses. This limit includes the aggregate of Route 53 Resolver DNS Queries, Instance Metadata Service (IMDS) requests, Amazon Time Service Network Time Protocol (NTP) requests, and Windows Licensing Service (for Microsoft Windows based instances) requests.
This limit is per instance (or more specifically per network interface). You can check it with ethtool -S ens5 | grep linklocal (I used ens5 but any interface should work).

When we see this value increase, it indicates packets to these link-local services were were dropped. When recreating this type of effect with curl, you see the result come back with an HTTP 000 response code, which could also be any number of other things too!
This value is reset when the instance is restarted, so if you have any value then you've hit this limit since your last restart.
What Was the Solution
Honestly, the solution is kind of boring. A simple cron job was set up to run every few minutes. It fetched credentials from the metadata service and stored them in a file for Ansible to use. It wasn't exactly perfect, but it was very fast to set up and allowed us to keep our existing multiplexing settings. Down the line, we may revisit, but like any other team in the space, our "to-do" list is endless.
Exposing the linklocal_allowance_exceeded metric is also a good move here whether that's in DataDog, CloudWatch, etc. That lets you know that you may need to take action or you had a particularly bursty load of traffic to your DNS resolver or the metadata service.
Conclusion
Anti-climatic endings aside, I hope this bit of information was useful. Having even a brief write-up with this type of information would have been helpful during troubleshooting, since no matter what we searched, we hadn't considered that a foundational service like IMDS could have throttled us.
