It is that time of year again. No, not the annual deploy freeze. It’s time for HackerOne to conduct its annual disaster recovery test.

Every year, the team simulates a critical failure in us-west-2. This is a significant failure, similar to GCP’s Europe-west9 outage earlier this year. During the procedure, we conduct a failover to us-east-2 and test our critical systems, such as payouts, report submission, and control panel operations.
Though it represents a serious topic, we generally try to bring some fun to the process. Consider last year’s scenario (Generated by “old-school” ChatGPT 3):

In this case, the team based in the Netherlands was paged with the hypothetical outage at 13:02 UTC and immediately began triaging the outage. Upon realizing the criticality of the disaster, they initiated the severity 1 disaster recovery plans and began working towards recovery.
This is a good place to talk about disaster recovery plans. Every company should have them. You never know when an europe-west9 or us-east-1 failure is going to happen. Even if you don’t have “mission critical” operations like public safety or finance, an actual regional failure may take weeks to recover fully. It’s likely your business can’t survive being down for weeks.
It’s daunting to consider creating a disaster recovery plan, especially if you are part of a small team. The cloud providers have pretty decent documentation on the topic: Both Disaster Recovery of Workloads on AWS: Recovery in the Cloud and Disaster recovery planning guide(From Google) stand out as decent resources. If you have an enterprise contract, this would be a great collaboration between your team and the AWS team.
The thing to keep in mind is that disaster recovery is an iterative process — continuous testing and improvement. Start small, perhaps the initial version is replicating your data stores (S3 buckets, databases, etc) since compute resources might be easier to recover than data. On the next test, you add compute resources. In another test you find that you can improve by having a warm standby of a particular EC2 machine in your DR region, so you add that and reduce the recovery time by a measurable amount.
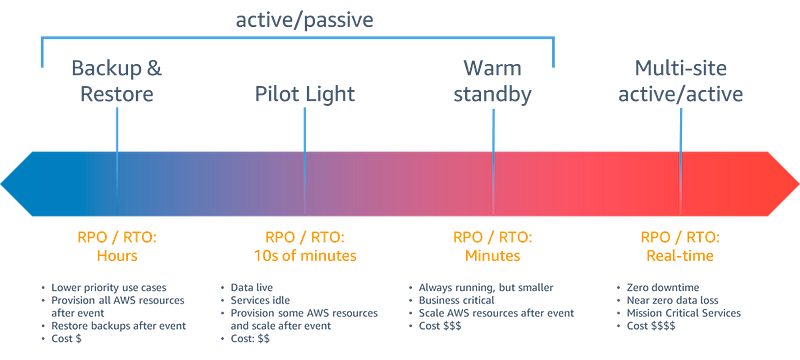
Having an idea of your required recovery time objective (RTO) and recovery point objective (RPO) is critical. The values need to be realistic and meaningful to the business. You can say you have an RTO of 1 minute, but if you don’t have the business need for that level of recovery, then having that level of recovery is pointless (and potentially costly!)
Figuring out what you should use for your RPO and RTO will be a big decision. It needs to be more than your team and more than engineering. It’s a business decision. These numbers will be communicated by the sales team and will be used by prospective customers when comparing you to alternatives. Different components will likely have different values. Starting small is the best option here.
Once you figure out your RPO and RTO, you can choose your DR approach. For many companies, a “Backup & Restore” or “Pilot Light” strategy is all that’s needed. As noted on the below chart, the further right you go, the costlier the implementation.
HackerOne has a pretty robust set of plans to handle various disasters, not just Amazon regional outages. It’s surprisingly refreshing to see not only that the plans exist, but they are also revisited and tested regularly.
In my personal experience, only the most mission-critical of businesses have exercised their disaster recovery plans. HackerOne is not typical in this case. There is a strong culture of testing and pushing to the limits. The tests, in this case, are tested at least annually.
For many companies, it’s expensive to conduct these tests. They are invaluable, though, with the experience and comfort that the dry runs bring. Leaders rarely see the benefit until, of course, the disaster happens for real.
Getting back to the team working on recovering the application, they have created the infrastructure and moved on to application deployment. Hackerone uses Ruby, which means Capistrano is the tool of choice here.
A lot of changes have happened since the last disaster recovery test. No architecture is static, and HackerOne’s isn’t either. With over 11,000 commits to our primary application since the last test and well over 1,000 for just our infrastructure as code repo, the infrastructure isn’t the same. Frequent testing helps reduce the number of issues that come from these updates.
In the end, we successfully hit the internally advertised goal that we were aiming for. It’s not quite as good as the team would have liked though. As is typical for these exercises, we took away a ton of experience and improvements we can make to improve the speed and efficiencies even more.
No disaster recovery plan is perfect, and each year, the team takes detailed notes on discoveries. These notes and experiences are discussed in a retrospective that we schedule very soon after the exercise.
Some things we discuss include:
- What went well?
- What did not go well?
- How can we improve?
- What was different (both good and bad) from last time?
- Were there any surprises?
One of my favorite things about these learnings is that the team makes it all public for company consumption. Everyone can view, comment, and ask questions about our approach and what we plan to change to do better.
Every company should have a disaster recovery plan in some level of detail. It should also be practiced on some cadence, but at the end of the day, it’s a business decision to invest and test disaster recovery. Leaders in the organization need to ensure the teams have the space and safety to take on these important functions.
