
How to manage multi-region S3 on day 0, day 1, and beyond
TLDR
- Whether starting a fresh project or enhancing a project that has a lot of mileage, the data layer should be one of the first ones tackled with respect to multi-region and disaster recovery.
- Greenfield projects are straightforward to configure and manage. It can be as few as just 2 or 3 more Terraform resources. For more flexibility at the cost of simplicity, we can add bi-directional replication and multi-region access points.
- Existing projects are a little more complicated but can be accomplished with not too much more work.
- Check out the sample repos here:
mencarellic/terraform-aws-s3-multi-region/day-0-dual-deployment
mencarellic/terraform-aws-s3-multi-region/day-0-bucket-replication
mencarellic/terraform-aws-s3-multi-region/day-1-existing-replication
Setting the Stage
Whether you are starting a project greenfield or working with a bucket that is celebrating its thirteenth birthday, you should consider what your data layer looks like through a multi-region and disaster recovery lens. Of course, S3 touts its durability (99.999999999% — 11 9’s!), and through its multiple availability zone design, there is very high availability; however we have certainly seen regional S3 outages.
In this article, I’ll explore what implementing multi-region S3 looks like for both existing and new buckets.
New Buckets
Starting with the easy scenario first:
Assume you are at a company based out of a single region, us-east-2. The company has been successful in a single region and has weathered most major Amazon outages with minimal reputational damage. The company is starting up a new web project, and you’re tasked with creating the S3 buckets for the static assets. The catch is that your manager asked you to design it with disaster recovery in mind in case us-east-2 ever has an outage.
The Approaches
At the start the solution seems simple: Create two buckets and just deploy to both of them.
In reality, that’s not exactly true. There’s a decision that needs to be made before any buckets are created. Do you augment your deployment pipeline to deploy to both buckets, or do you leverage AWS native S3 bucket replication? There are definitely benefits and drawbacks to each approach; for example, what if the deployment pipeline breaks halfway through the deployment of the change when uploading to the bucket in the DR region, or what if a manual change is made in us-east-2 and replicated to us-west-2? I won’t discuss the pros and cons too much since adoption ultimately falls to the design paradigms of you and the business at the end of the day.
Setting the stage for the examples below, each one will have a pair of versioned, encrypted buckets that have public access disabled. Additionally, a KMS key for each region will be created.
Deploying to Multiple Buckets with Your CI/CD Pipeline
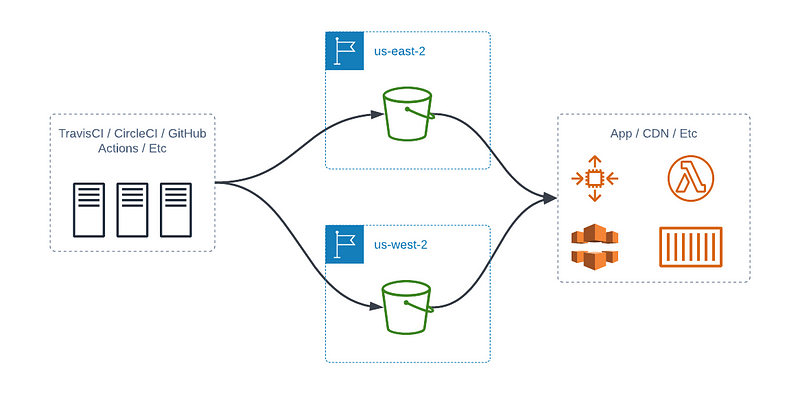
This is probably the more straightforward system to set up. In most deployment systems, you can add additional targets to deploy your artifact. The two buckets in AWS are treated as separate and do not interact with each other in any way.
The Terraform is equally simple. It’s only two buckets. You can see the sample here: mencarellic/terraform-aws-s3-multi-region/day-0-dual-deployment
Using S3 MRAP and Bi-Directional Replication
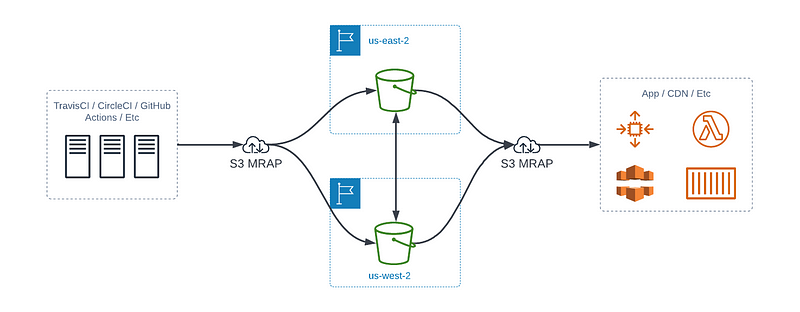
This strategy is a little more complex, but I think it has the added benefit of not needing your CI/CD tool to implement data resiliency. Let AWS and S3 worry about that; after all, they are the professionals at it.
Your artifact building pipeline pushes the artifact to two (or more) buckets that are tied together with a multi-region access point. The buckets use bi-directional replication, and from there, your deployment tool uses the same access point to deploy the code. This method has the additional safety of continued operations even if a region’s S3 service is down.
The Terraform for this is a little more complex. Mainly in the form of the inclusion of the aws_s3control_multi_region_access_point resource and the replication configuration to support bi-directional replication of the buckets.
First the multi-region access point resource. This is a straight-forward resource, just probably not common yet since it has a pretty narrow use case and is relatively new (re:Invent 2021). You can find the Terraform docs for the resource here: aws_s3control_multi_region_access_point.
resource "aws_s3control_multi_region_access_point" "app-artifact" {
details {
name = "app-artifact"
region {
bucket = aws_s3_bucket.app-artifact-east-2.id
}
region {
bucket = aws_s3_bucket.app-artifact-west-2.id
}
}
}Next, the replication configuration. The configuration exists in both buckets since we’re doing bi-directional replication. The replication also needs an IAM role for the replication to occur.
Note: In versions before the 4.X refactor of the AWS provider this was much more difficult to achieve since to apply bi-directional replication, you would either have to create the buckets first. Then add the configuration or accept that the first Terraform plan/apply would fail since there will be a race condition of both buckets having a replication configuration that requires the destination bucket to exist already before it could complete.
The configuration for the replication resource is straightforward as well (found here: aws_s3_bucket_replication_configuration). The catches come from the IAM policy and the KMS encryption.
In your IAM policy you’ll want to ensure you’re granting permission for the S3 actions for both buckets and their children objects:
statement {
sid = "CrossRegionReplication"
actions = [
"s3:ListBucket",
"s3:GetReplicationConfiguration",
"s3:GetObjectVersionForReplication",
"s3:GetObjectVersionAcl",
"s3:GetObjectVersionTagging",
"s3:GetObjectRetention",
"s3:GetObjectLegalHold",
"s3:ReplicateObject",
"s3:ReplicateDelete",
"s3:ReplicateTags",
"s3:GetObjectVersionTagging",
"s3:ObjectOwnerOverrideToBucketOwner"
]
resources = [
aws_s3_bucket.app-artifact-east-2.arn,
aws_s3_bucket.app-artifact-west-2.arn,
"${aws_s3_bucket.app-artifact-east-2.arn}/*",
"${aws_s3_bucket.app-artifact-west-2.arn}/*",
]
}If you’re doing KMS/SSE, you can enforce it with the following conditions in the above statement:
condition {
test = "StringLikeIfExists"
variable = "s3:x-amz-server-side-encryption"
values = ["aws:kms", "AES256"]
}
condition {
test = "StringLikeIfExists"
variable = "s3:x-amz-server-side-encryption-aws-kms-key-id"
values = [
aws_kms_key.bucket-encryption-west-2.arn,
aws_kms_key.bucket-encryption-east-2.arn
]
}Which, speaking of encryption, you need to remember to include kms:Encrypt and kms:Decrypt permissions in your IAM policy:
statement {
sid = "CrossRegionEncryption"
actions = [
"kms:Encrypt",
"kms:Decrypt"
]
resources = [
aws_kms_key.bucket-encryption-west-2.arn,
aws_kms_key.bucket-encryption-east-2.arn
]
condition {
test = "StringLike"
variable = "kms:ViaService"
values = [
"s3.${aws_s3_bucket.app-artifact-east-2.region}.amazonaws.com",
"s3.${aws_s3_bucket.app-artifact-west-2.region}.amazonaws.com"
]
}
condition {
test = "StringLike"
variable = "kms:EncryptionContext:aws:s3:arn"
values = [
"${aws_s3_bucket.app-artifact-east-2.arn}/*",
"${aws_s3_bucket.app-artifact-west-2.arn}/*"
]
}
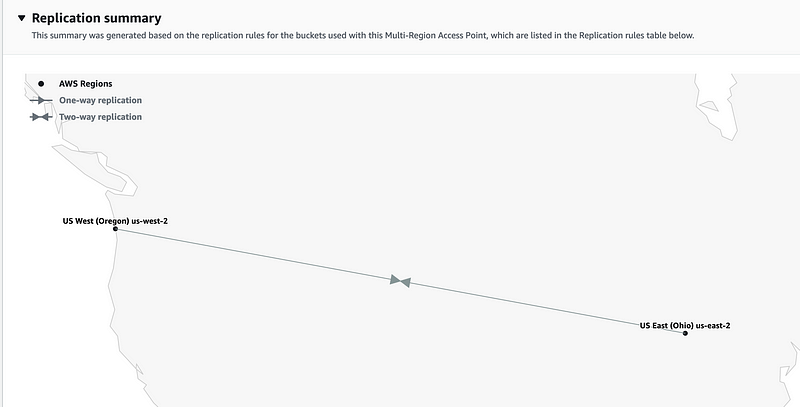
}
The full set of Terraform code can be found at mencarellic/terraform-aws-s3-multi-region/day-0-bucket-replication
Existing Buckets
Now the interesting scenario:
The new application you helped build to be multi-region from day 0 has taken off, and now you’ve been asked to help add disaster recovery to the legacy apps. Sounds easy, except the existing legacy bucket has terabytes of data that would need to be replicated.
So, realistically, an application might not have terabytes of data that is absolutely required for complete disaster recovery, but also who would want to sift through countless files in a bucket that is almost as old as S3 to find the relevant files?
Your existing applications infrastructure looks pretty standard: S3 bucket, public access block, KMS encryption. The first thing we need to do is stand up the secondary region’s bucket. We should probably enable replication so that anything going forward from today is replicated. This is done exactly as it was done above: with a aws_s3_bucket_replication_configurationresource.
Next, you’ll want to get an inventory of everything in the source bucket. We’ll do this with the aws_s3_bucket_inventory resource (documentation here: aws_s3_bucket_inventory). You’ll notice that our destination is actually a whole separate bucket. When taking on this endeavor, you’ll probably want to have all of your inventories go into the same place so you’ll know where they all are.
resource "aws_s3_bucket_inventory" "app-artifact-east-2" {
bucket = aws_s3_bucket.app-artifact-east-2.id
name = "EntireBucketDaily"
included_object_versions = "Current"
schedule {
frequency = "Daily"
}
destination {
bucket {
format = "CSV"
bucket_arn = aws_s3_bucket.inventory.arn
}
}
provider = aws.east-2
}Once you have an inventory file, you can use an S3 batch operation to copy the files in the inventory file from the legacy bucket to the new bucket.
Note: The COPY batch operation is new as of February 8, 2022. You can read more about it in the AWS News post here: NEW — Replicate Existing Objects with Amazon S3 Batch Replication. Before this release, there were two options, and neither were very good: Manually copy the files using a script that takes time and costs money, or open a support ticket and hope they can get to it. When my team opened a request for this before batch job support, we were told it would be several weeks before they could get to it.
Regrettably, we can’t configure batch operations via Terraform just yet. There is an open issue in the Terraform provider though: Feature Request: Support for S3 Batch Operations. We can, however, configure the IAM role for the batch operation.
The IAM role is pretty easy:
- An assume role policy for
batchoperations.s3.amazonaws.com s3:GetObject*for the source buckets3:PutObject*for the destination buckets3:GetObject*for the inventory bucket- If you are configuring a job report, you’ll want to allow
s3:PutObjectfor an S3 destination too. I use the inventory bucket for this kms:Encryptandkms:Decryptfor encryption and decryption if there is encryption enabled
After the buckets and role are correctly configured, you’ll want to navigate to the S3 Batch Operations console.
If desired, you could change tags, metadata, or storage class. But if we use this for an active/active configuration, we’ll just leave everything as the default value.
After the job is created, it will run through a series of checks and then wait for your confirmation before executing. After confirmation, the job starts, and you’re able to monitor the status from the job status page. It runs pretty quickly. In my sample, I copy 1,000 objects in 14 seconds. Admittedly they are essentially empty objects, but it is still pretty fast.
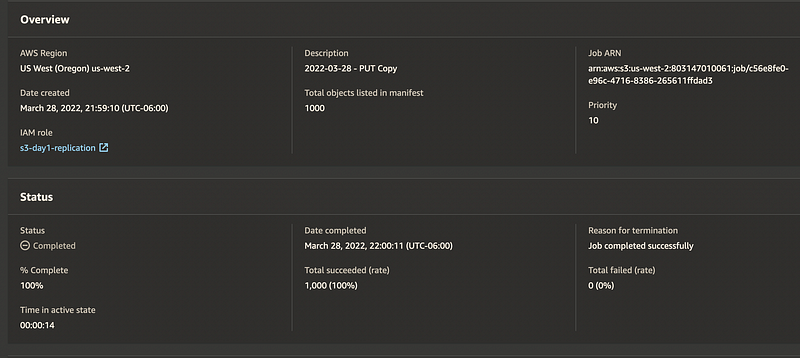
Regarding other options for replicating existing buckets, as stated above, alternate options would be to set up replication between the source and destination buckets and set up either a lambda or batch job that touches each file to trigger bucket replication from the original bucket to the new bucket. You can do the same in an EC2 instance or even from a local laptop though those options are less recommended.
There are some negatives with this approach, mainly in that you’re recreating something that exists natively in AWS already, and I’m sure you have better things to be doing than recreating the wheel.
